

Figure: Benchmark comparisons from Wang (2025), showing GPT-5’s performance on text and multimodal reasoning tasks relative to GPT-4o and pre-licensed human experts.
Summary (TL;DR )
A recent study (Wang, 2025) positions GPT-5 as a generalist multimodal reasoner — outperforming pre-licensed human experts in structured tests of medical decision-making. While evaluation standards vary and results are not yet from real-world clinical practice, the trend is unmistakable: AI models are moving closer to competing directly with human expertise in defined reasoning tasks. The challenge now is less about capability and more about how we validate, govern, and integrate these systems responsibly. AI will not replace doctors, but it is redefining the role of expertise — shifting clinicians from being sole holders of knowledge to becoming sense-makers, guides, and decision partners.
1. A Milestone in AI’s Medical Reasoning
For decades, AI in healthcare has been framed in terms of potential. Diagnostics, imaging, decision support — all promised but rarely delivered at scale. GPT-5 represents a shift from potential to demonstrated progress.
Our Publication


The Wang (2025) study evaluated GPT-5 under a unified protocol across both text-based and visual medical reasoning tasks. The results were striking: GPT-5 consistently outperformed pre-licensed human experts, achieving higher accuracy in structured benchmarks. For those interested in the benchmarks and detailed results, see the Appendix below.
This doesn’t mean AI is “better than doctors.” Instead, it signals that AI has crossed a threshold: it can now perform certain reasoning tasks at — or above — the level of human trainees under test conditions.
2. Why Multimodality Matters
Healthcare is inherently multimodal. A single clinical decision may draw on lab results, imaging, patient history, and physician notes. Earlier models struggled to combine these inputs; GPT-5 is among the first large-scale models to integrate multiple data types under one reasoning framework that is accessible to public.
This matters because real-world medicine is rarely about one dataset in isolation. A patient’s diagnosis or treatment plan depends on weaving together disparate signals. GPT-5’s ability to handle text + image + structured data is a step closer to reflecting how clinicians think and work.
3. Testing Standards and the Bigger Picture
The featured figure above of this blog summarises GPT-5’s relative performance across text and multimodal tasks, compared with GPT-4o and human experts. It shows not just incremental improvement, but a shift toward consistency across modalities.
It’s important to note that evaluation standards for LLMs in medicine are not uniform. Some studies — like Wang (2025) — use structured synthetic datasets designed to test reasoning consistency. Others, such as NIH-led benchmarking, highlight uneven performance across specialties or under more complex, less curated conditions.
This variation can confuse the picture. But one point is clear: across studies, the trend line is upward. Models are not static; with each iteration, they are closing the gap between computational reasoning and human expertise.
The right interpretation is not to overstate readiness, but to recognise the direction of travel. AI is no longer a question of “if” it will compete in defined domains of expertise, but “how” we will manage its integration responsibly.
go to: | Start | Top of This Section | End
4. What This Means for Expertise
For centuries, the medical profession has been defined by the mastery of knowledge: memorising, synthesising, and applying vast amounts of information to individual cases. If AI can now match or exceed human reasoning in structured settings, the definition of expertise shifts.
- Doctors will still be essential. But their value will evolve from knowledge memorisation toward sense-making, contextualisation, and empathy.
- Patients will gain more access to knowledge. Carolina Millon’s story (Blog 1) illustrates how patients can already use AI to understand their condition and prepare for consultations.
- Systems will need new guardrails. If AI contributes reasoning, it must be tested, validated, and overseen with the same rigour as any other clinical tool.
5. The Caution: Capabilities ≠ Deployment
While the results are promising, they come from controlled conditions. Real-world medicine is messy, incomplete, and full of uncertainty. Clinical deployment of GPT-5 will require:
- Rigorous validation in diverse, real-world settings.
- Clear guardrails for safe, ethical, and equitable use.
- A strong role for human oversight and decision-making.
In plain language: AI can provide insights, but it cannot replace the role of trained clinicians. Doctors remain the final decision-makers — interpreting AI outputs, weighing them against real-world context, and ensuring care is guided by expertise, ethics, and patient values. At the same time, models like GPT-5 can help patients and doctors access the same high-quality reasoning — making healthcare conversations more collaborative, efficient, and informed.
6. Beyond the Benchmarks: Broader Implications
The implications of GPT-5’s performance go beyond test scores. They touch on trust, power, and professional identity in healthcare:
- Trust: Patients need to believe that AI-assisted care is safe and reliable.
- Power: As knowledge becomes more accessible, the balance shifts from hierarchical to participatory medicine.
- Professional identity: Clinicians must adapt — moving from being knowledge gatekeepers to becoming partners, strategists, and advocates.
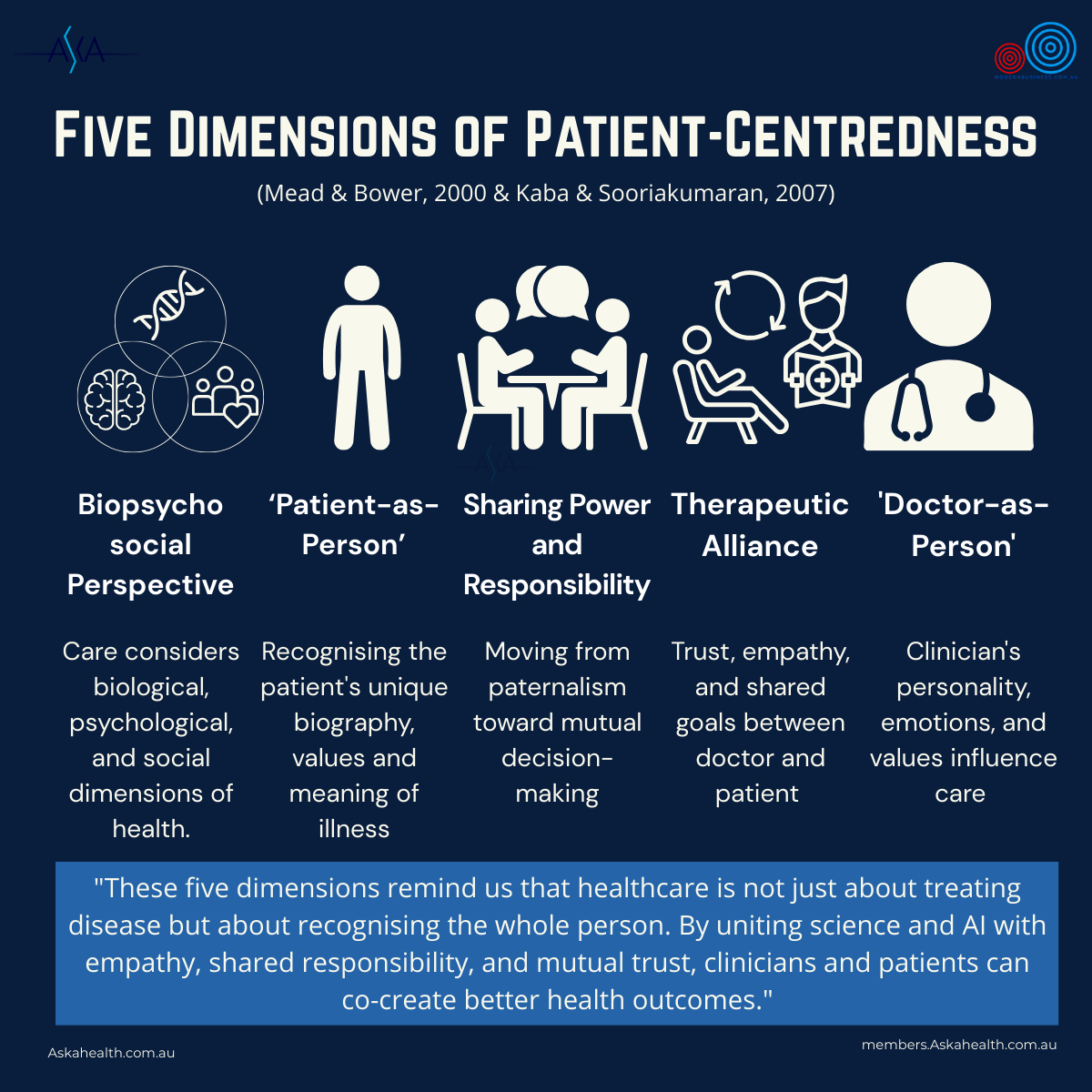
This echoes themes from Blog 2 (the Five Dimensions of Patient-Centred Care). AI does not diminish those dimensions — it strengthens them by freeing space for empathy, trust, and collaboration.
7. Connecting the Dots
This blog is not an endpoint, but a bridge. The first three articles traced the evolution of the doctor–patient relationship: Carolina’s story, the Five Dimensions, and the historical leap from Ancient Egypt to AI. This fourth article introduces the evidence: GPT-5’s breakthrough in multimodal reasoning.
In Blog 5, we will connect all four threads — story, framework, history, and research — into a bigger picture of how healthcare conversations are being reshaped. And in Blog 6, we’ll go one step further with the Patient Journey Communications Framework — a practical model that shows how communication dynamics are evolving in the AI era. Because of its value, this final guide will be available exclusively (but still free) through our membership portal. This ensures it is shared within a community of people who are serious about co-creating better care, rather than as content for quick clicks or noise.
Conclusion: From Capability to Responsibility
GPT-5 marks a milestone: AI can now perform certain medical reasoning tasks at or above the level of human trainees under structured conditions. But capability is not the same as deployment. The real question is not whether AI can compete with human expertise, but how we will validate, govern, and integrate it responsibly.
For practitioners, the shift is profound. Expertise will no longer be defined by what is memorised, but by how effectively clinicians can contextualise, interpret, and connect — bringing the human elements of empathy, trust, and judgment that AI cannot replicate.
The message is clear: AI supports, but humans decide. The future lies in partnership.
go to: | Start | Top of This Section | End
Relevant Blogs in This Series
👉 If you’re ready to continue, Blog 5, will connect the all four threads so far to complete the story.
Here are the other blogs in this series:
1️⃣ From Patients to Partners — How informed patients like Carolina Millon are reshaping care.
2️⃣ The Five Dimensions of Patient-Centred Care — A framework for what “good care” looks like in practice.
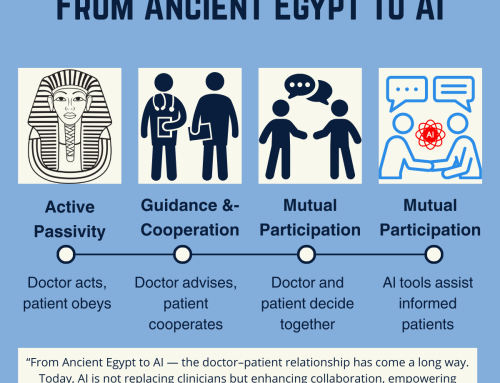
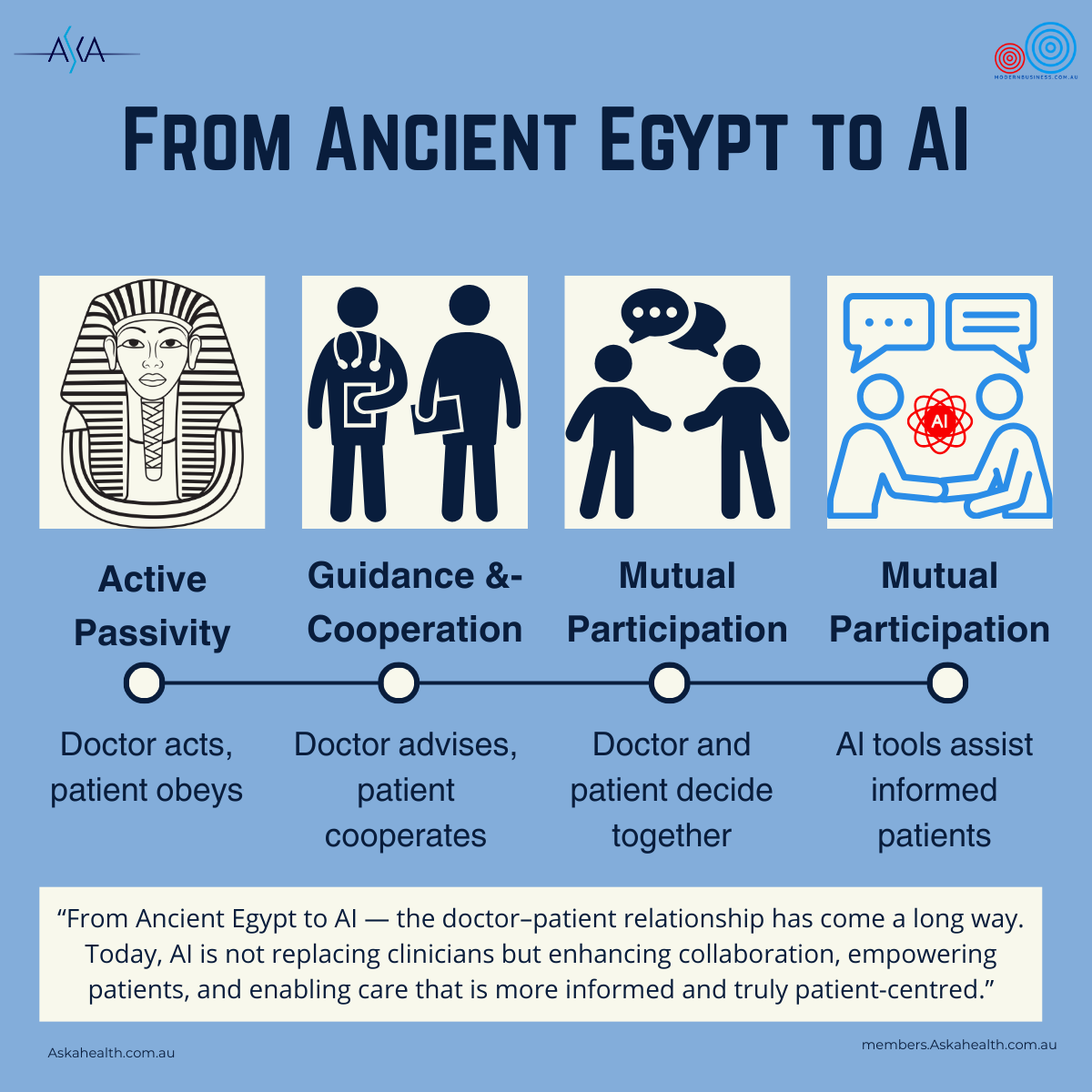
3️⃣ From Ancient Egypt to AI — The fastest leap in the doctor–patient relationship in history.
4️⃣ Breaking Barriers — How GPT-5 is advancing multimodal medical reasoning beyond human expertise. (This Blog)
5️⃣ From Patients to Partners — AI’s real-world impact on healthcare.
6️⃣ Understanding the Patient Journey — A new framework for communication in modern healthcare.
🌍 We hope this series serves as a mini masterclass for practitioners and healthcare innovators — helping to reimagine healthcare and shape it for the better.
Before you move on, we’d love to hear from you:
- What are your thoughts on the evaluation from S. Wang (2025) — and our take on AI’s progress in supporting patients and doctors?
- What implications do you see for your work, your organisation, or the wider healthcare industry?
- How would you approach testing a model like GPT-5 in your own context?
💬 Your feedback will help refine this series and ensure it delivers maximum value for medical practices and healthcare innovators. Please share your comments below — your insights are an important part of shaping this conversation.
go to: | Start | Top of This Section | End
Join the Movement
If this series of blogs has sparked your imagination about how healthcare delivery could be transformed — making it more accessible, affordable, and equitable while also reducing burnout among healthcare professionals — we invite you to connect with the Co-Create Care Movement.
This growing community brings together healthcare innovators, leaders, clinicians, and forward-thinkers who are exploring how AI can be used responsibly to empower patients, support clinicians, and improve outcomes.
Connect with Co-Create Care movement.
→ Facebook Group: Aligning for Excellence
→ Community Link – Meetup Discussions @ AI in Practice (Our Fortnightly Online forum for live discussions)
Together, we can shape a future where healthcare isn’t just sustainable—it’s remarkable.
📌 Appendix: What Was Tested and How GPT-5 Performed
What Was Tested?
The Wang (2025) study focused on multimodal reasoning — the ability to combine and interpret different types of medical information. This includes:
- Text-based reasoning (e.g., medical licensing exam questions, case narratives)
- Image interpretation (e.g., radiology scans)
- Integrated cases combining text, lab values, and medical images
The benchmarks used included respected datasets such as MedQA, USMLE sample exams, MedXpertQA, and VQA-RAD. These are the same kinds of tests used to assess both AI models and medical trainees.
How Did GPT-5 Perform?
When compared with its predecessor GPT-4o — and even with trained human experts — GPT-5 showed remarkable improvements:
- Text-based reasoning: GPT-5 scored as high as 95.8% on MedQA, surpassing human passing thresholds for USMLE exams.
- Multimodal reasoning: In tasks requiring integration of text and images, GPT-5 demonstrated +24% to +29% gains in reasoning and understanding compared to GPT-4o. Save
- Human comparison: GPT-5 outperformed pre-licensed human experts in both reasoning and comprehension on most benchmarks.
go to: | Start | Top of This Section | End
Reference
Wang, S., Hu, M., Li, Q., Safari, M. and Yang, X. (2025). Capabilities of GPT-5 on Multimodal Medical Reasoning. [online] arXiv.org. Available at: https://arxiv.org/abs/2508.08224 [Accessed 17 Aug. 2025].
Tian, S., Qiao, J., Yeganova, L., Lai, P., Zhu, Q.-M., Chen, X., Yang, Y., Chen, Q., Kim, W., Comeau, D.C., Rezarta Islamaj Doğan, Kapoor, A.K., Gao, X. and Lu, Z. (2024). Opportunities and challenges for ChatGPT and large language models in biomedicine and health. Briefings in Bioinformatics, 25(1). doi:https://doi.org/10.1093/bib/bbad493 [Accessed 17 Aug. 2025].
go to: | Start | Top of This Section | End



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment